


Hello guys! This is Nikhil Nandam with my first ever article on my personal blog page on HashNode. So through this article, I wish to provide idea of the foundations for Machine Learning used in Data Science. So without any further ado, lets dive right in!
What is Machine Learning?
Well, Machine Learning is a branch of Artificial Intelligence that constantly improves its algorithm performance with as minimal human intervention as possible using data gathered from real world. But Machine Learning with respect to Data Science involves predicting values based on various patterns and similarities that the algorithm finds and trains on the training data. For example: Predicting the price of a house, given the various features that describe a house such as its area(in any metric), number of bedrooms, etc.
What is a model?
A model is usually a file that is trained on a set of data(training data) during the training phase to recognise and identify certain patterns, similarities and correlations between various features of the data using certain algorithms that can be fine-tuned to provide best results for the given instance of data.
Terminology
Target Class/Value(s): The label that is being predicted by the model.
Input features: The values of a data instance that the model does computations in order to associate it with a target value. NOTE: THIS CANNOT INCLUDE THE TARGET VALUE.
Training phase: The most important step in the pipeline where we choose a model for the data to train on and provide it with 2 sets of data(one: the features separated from their corresponding target values, second: the corresponding target values) so the model can learn how various features are correlated with the target value and accordingly adjust its coefficients automatically to improvise on it ability to associate a data instance with its class given its input features.
Testing phase: This step involves analysing who well our model performs on new previously unseen data during the training phase and then adjusting the model parameters to improve the accuracy metric we are trying to maximise.
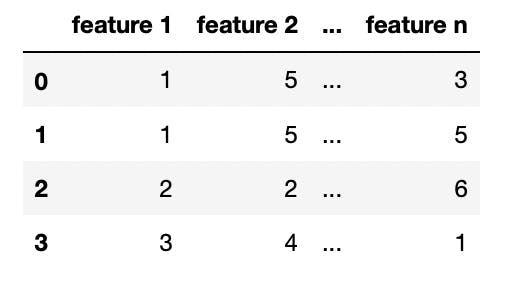
Typically, a dataset would be of this format
 and after separating the target values from the features, our input feature set and target value set looks like this
and after separating the target values from the features, our input feature set and target value set looks like this

Types of Machine Learning Algorithms
Machine Learning models can be divided into main 2 categories:
Supervised Learning: The class of machine learning models that need the target value(s) for the corresponding input features during the training phase to yield a model. K-Nearest Neighbours and Linear Regression are a few examples for these category of learning models.
Unsupervised Learning: The other class of machine learning models that don't need target value(s) during the training phase. K-Means Clustering is one such example of this class of learning models.
We are going to focus mainly on Supervised Learning models as far as this article goes.
Categories of Supervised Learning Models
Supervised Learning Algorithms can be classified into mainly 2 sub divisions depending on the value(s) that are predicted as outcome.
Classification Algorithms: This constitutes the set of algorithms where the predicted value(s) are discrete values (not continuous). Example: Predicting a mail is spam or not, predicting whether a fruit is an apple or not. There are sub classes with classification algorithms like binary classification(where the target value represents a ‘positive-class’ and a ‘negative-class’), multi-class classification(where the target value is strictly one of the many subclasses that exist within the data) and also multi-label classification(where one data instance can have more than one class associated with it).
Regression Algorithms: As you might guess, these are the set of algorithms where the predicted value(s) are continuous. The housing example mentioned above is a regression task.
Feature Preprocessing / Feature Extraction
This step involves finding the features that are highly correlated to our target value, adding valid features, extracting many features from a single feature, dropping some of the features that don't yield performance improvement on our model, transforming some features into new features etc.
For example, in classifying whether a mail is a spam or not, some features like length of text, number of digits, and number of non-word characters are not available implicitly and we need to extract those features from the mail text using any methods at your disposal(like regex).
Below is the code snippet that extracts number of digits from a mail text for each instance in the dataset.
df['num_digits'] = (df['text'].str.findall(r'[\d]{1}')).str.len()
*where 'df' is the dataframe that contains text as one of its columns(input feature).
Train-Test Split
Okay, now let us assume you have a trained model. How do you know if your model is good at predicting the target value for any data that was not seen during the training data? Here comes the testing phase where we calculate how well the model performs on new unseen data. For that purpose we split our dataset into training set and test set before the training phase and train the model exclusively on that training set, basically preventing any knowledge of information in the test set from the model during the training phase. The fraction of data that is separated out as test set is typically 1/3rd (i.e 33%).
Essentially any leakage of information from the test set to the model is called Data Leakage and this needs to be dealt very seriously for performance reasons.
Below is the code to split a dataset into training and test sets using sklearn's train_test_split function.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
*where X and y correspond to the input_features and target_values respectively.
Fitting the model (Training phase)
This stage involves training the model on the training data, allowing the model to adjust its settings and parameters to improvise at its ability to predict the right target values associated with the data instance in the training data.
Below is the code snippet that demonstrates this.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=10)
model.fit(X_train, y_train)
Overfitting and Underfitting
This is another critical aspect that we need to consider.
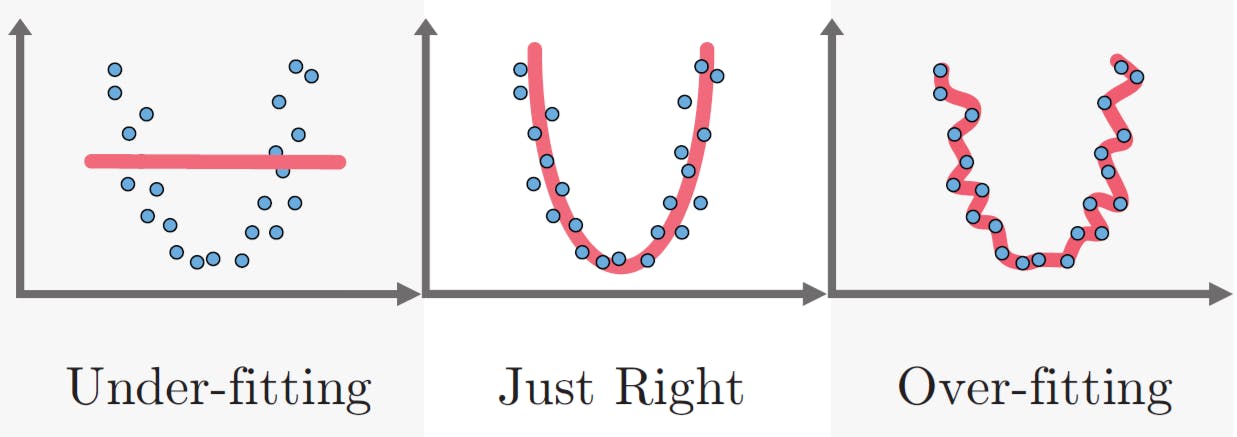
What is overfitting?
The fine tuning of model in way that the model is intolerant to small change in values of the input features is called overfitting. Computing performance score on training data yields high scores and one might assume the model is simply superb. This might seem good but is actually quite the opposite. Computing performance scores on the test data yields shockingly poor results. This is because the model is highly complex and doesn't generalise well on new data and has complex decision boundaries.
What is underfitting?
The over simplistic model that has high tolerance to noise but can't find similarities, patterns on any data is called underfitting. Unlike overfitting, underfitting leads to low training and test score.
Here is an image that illustrates this concept.
Model Validation
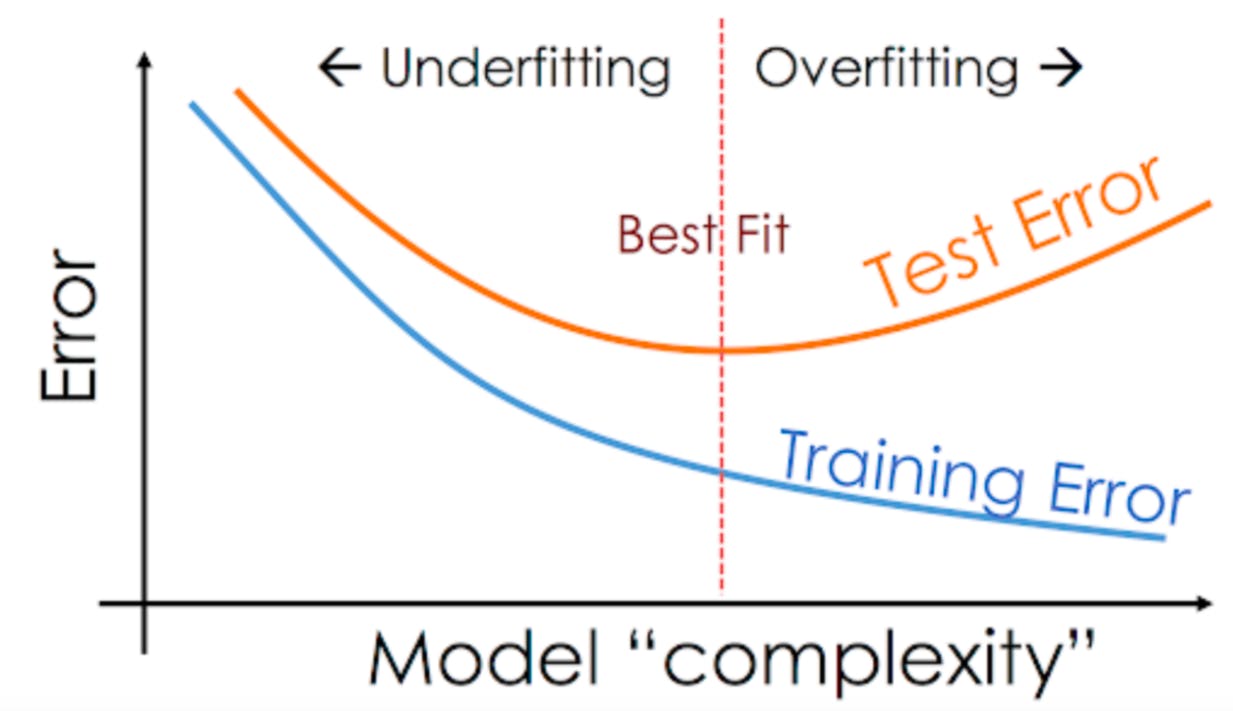
As mentioned earlier we evaluate a model's performance using certain metrics like accuracy, precision, recall, f1-score etc. We will not be going into details of how each metric is calculated in this article.
The image below perfectly depicts how the training score and test score of the model are impacted due to underfitting and overfitting and also the threshold to find the best fit for the model.
Below is the code snippet that calculates accuracy of a model on the test set
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
model = KNeighborsClassifier(n_neighbors=10)
model.fit(X_train, y_train)
print("Model's accuracy score on test set is {}".format(model.score(X_test, y_test)))
Typical Machine Learning Pipeline
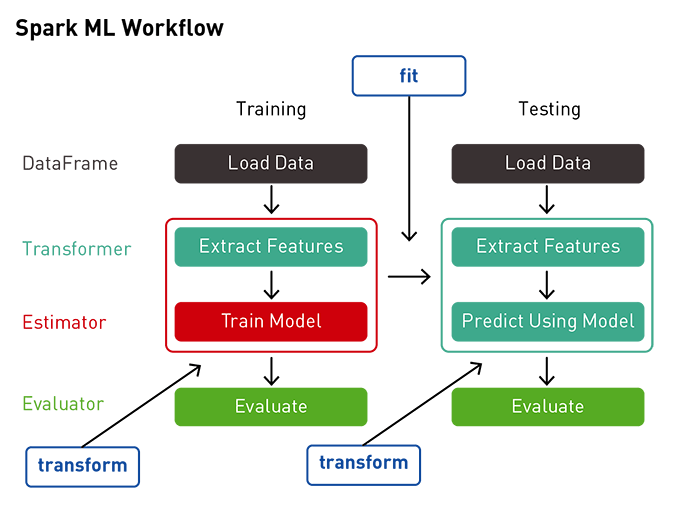
That's it guys, as far as this article is concerned. Please leave a like down below if you find this insightful. Leave your thoughts and suggestions down below. And as always, Happy Learning. 😁😄
